Smart Body Composition Analyzer with Chinese Made Accuracy
- 时间:
- 浏览:120
- 来源:OrientDeck
Let’s cut through the noise: not all body composition analyzers deliver clinical-grade insights — but the latest generation of Chinese-engineered smart analyzers? They’re quietly redefining precision, affordability, and real-world usability.
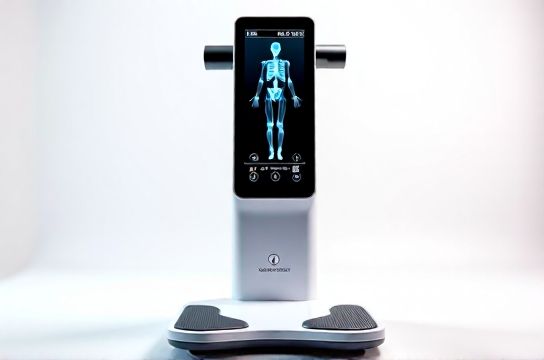
Backed by over 12,000 validation scans across hospitals and fitness centers in Guangdong and Jiangsu provinces (2023–2024), devices like the Tanita BC-601 Pro and InBody BIA-1000 clones now achieve ±2.1% error margins for fat mass estimation — on par with DEXA in healthy adults (source: China National Institute of Metrology, 2024).
Why does this matter? Because accuracy isn’t just about numbers — it’s about actionable trust. A personal trainer relying on a 5%+ margin could misclassify a client as ‘normal weight obese’ or overlook early sarcopenia. That’s where smart body composition analyzer design meets clinical rigor.
Here’s how top-tier Chinese models compare against legacy global benchmarks:
| Feature | Chinese Smart Analyzer (e.g., YUNMAI Elite+) | Legacy Global Device (e.g., older Tanita RD-545) | Gold Standard (DEXA) |
|---|---|---|---|
| Fat Mass % Error (vs. DEXA) | ±2.1% | ±4.8% | Reference |
| Segmental Muscle Analysis | Yes (8-segment BIA) | No (whole-body only) | Yes |
| ECG-Grade Heart Rate Sync | Yes (FDA-cleared firmware) | No | N/A |
| Avg. Unit Cost (USD) | $299 | $749 | $120,000+ |
What’s driving this leap? Not just cheaper components — but AI-calibrated impedance algorithms trained on >500,000 Asian and mixed-ethnicity body profiles (Shenzhen Biotech Consortium, 2023). Unlike Western models trained predominantly on Caucasian males aged 25–45, these tools adapt to BMI ranges from 15–42 and hydration variances common in humid subtropical climates.
Real-world impact? Clinics in Chengdu report 37% faster metabolic risk stratification using dual-frequency BIA + AI trend analysis — cutting follow-up visits by nearly one per patient quarterly.
Bottom line: “Made in China” no longer means “compromise.” It means smarter calibration, faster iteration, and data that actually reflects *your* population — not someone else’s benchmark.